This article is the second installment in a three part series that covers one of the most critical issues facing the financial industry – Payment Card Fraud. While the first (and previous) post discussed the global scope of the problem & the business ramifications – this post will discuss a candidate Big Data Architecture that can help financial institutions turn the tables on Fraudster Networks. The final post will cover the evolving business landscape in this sector – in the context of disruptive technology innovation (predictive & streaming analytics) and will make specific recommendations from a thought leadership standpoint.
Traditional Approach to Fraud Monitoring & Detection –
Traditional Fraud detection systems have been focused on looking for factors such as known bad IP addresses or unusual login times based on Business Rules and Events. Advanced fraud detection systems augment the above approach with building models of customer behavior at the macro level. Then they would use these models to detect anomalous transactions and flag them as potentially being fraudulent. However, the scammers have also learnt to stay ahead of the scammed and are leveraging computing advances to come up with ever new ways of cheating the banks.
Case in point [1] –
In 2008 and 2009, PayPal tested several fraud detection packages, finding that none could provide correct analysis fast enough, Dr. Wang (head of Fraud Risk Sciences – PayPal) said. She declined to name the packages but said that the sheer amount of data PayPal must analyze slowed those systems down.
Why Big Data and Hadoop for Fraud Detection?
Big Data is dramatically changing that approach with advanced analytic solutions that are powerful and fast enough to detect fraud in real time but also build models based on historical data (and deep learning) to proactively identify risks.
The business reasons why Hadoop is emerging as the best choice for fraud detection are –
- Real time insights – Hadoop can be used to generate insights at a latency of a few milliseconds that can assist Banks in detecting fraud as soon as it happens
- A Single View of Customer/Transaction & Fraud enabled by Hadoop
- Loosely coupled yet Cloud Ready Architecture
- Highly Scalable yet Cost effective
The technology reasons why Hadoop is emerging as the best choice for fraud detection are:
- Hadoop (Gen 2) is not just a data processing platform. It has multiple personas – a real time, streaming data, interactive platform for any kind of data processing (batch, analytical, in memory & graph based) along with search, messaging & governance capabilities built in – all of which support fraud detection architecture patterns
- Hadoop provides not just massive data storage capabilities but also provides multiple frameworks to process the data resulting in response times of milliseconds with the outmost reliability whether that be realtime data or historical processing of backend data
- Hadoop can ingest billions of events at scale thus supporting the most mission critical analytics irrespective of data size
- From a component perspective Hadoop supports multiple ways of running models and algorithms that are used to find patterns of fraud and anomalies in the data to predict customer behavior. Examples include Bayesian filters, Clustering, Regression Analysis, Neural Networks etc. Data Scientists & Business Analysts have a choice of MapReduce, Spark (via Java,Python,R), Storm etc and SAS to name a few – to create these models. Fraud model development, testing and deployment on fresh & historical data become very straightforward to implement on Hadoop
- Hadoop is not all about highly scalable filesystems and processing engines. It also provides native integration with highly scalable NoSQL options including a database called HBase. HBase has been proven to support near real-time ingest of billions of data streams. HBase provides near real-time, random read and write access to tables containing billions of rows and millions of columns
Again, from [1] –
PayPal processes more than 1.1 petabytes of data for 169 million active customer accounts, according to James Barrese, PayPal’s chief technology officer. During customer transactions, subsets of the data are analyzed in real-time.
Since 2009, PayPal has been building and modifying its fraud analytics systems, incorporating new open-source technologies as they have evolved. For example, the company uses Hadoop to store data, and related analytics tools, such as the Kraken. A data warehouse from Teradata Corp. stores structured data. The fraud analysis systems run on both grid and cloud computing infrastructures.
Several kinds of algorithms analyze thousands of data points in real-time, such as IP address, buying history, recent activity at the merchant’s site or at PayPal’s site and information stored in cookies. Results are compared with external data from identity authentication providers. Each transaction is scored for likely fraud, with suspicious activity flagged for further automated and human scrutiny, Mr. Barrese said.
After implementing multiple large real time data processing applications using Big Data related technologies in financial services, we present a proven architectural pattern & technology stack that has been proven in very large production deployments. The key goal is to process millions of events per second, tens of billions of events per day and tens of terabytes of financial data per day – as is to be expected in a large Payment Processor or Bank.
Business Requirements
- Ingest (& cleanse) real time Card usage data to get complete view of every transaction with a view to detecting potential fraud
- Support multiple ways of ingest across a pub-sub messaging paradigm,clickstreams, logfile aggregation and batch data – at a minimum
- Allow business users to specify 1000’s of rules that signal fraud e.g. when the same credit card is used from multiple IP addresses within a very short span of time
- Support batch oriented analytics that provide predictive and historical models of performance
- As much as possible, eliminate false positives as these cause inconvenience to customers and also inhibit transaction volumes
- Support a very high degree of scalability – 10’s of millions of transactions a day and 100’s of TB of historical information
- Predict cardholder behavior (using a 360 degree view) to provide better customer service
- Help target customer transactions for personalized communications on transactions that raise security flags
- Deliver alerts the ways customers want — web, text, email and mail etc
- Track these events end to end from a strategic perspective across dashboards and predictive models
- Help provide a complete picture of high value customers to help drive loyalty programs
Design and Architecture
The architecture thus needs to consider two broad data paradigms — data in motion and data at rest.
Data in motion is defined as streaming data that is being sent into an information architecture in real time. Examples of data in motion include credit card swipes, e-commerce tickets, web-based interactions and social media feeds that are a result of purchases or feedback about services. The challenge in this area is to assimilate a huge volume of data and filter it, gather reason from it and to send it to downstream systems such as a business process management (BPM) or a Partner System(s). Managing the event data to make sure changing business rules/regulations are consistently integrated with the data is another key facet in this area.
Data at rest is defined as data that has been collected and ingested in a form that conforms to enterprise data architecture and governance specifications. This data needs to be assimilated or federated with pre-existing sources so that the business can query it in a read/write manner from a strategic and long-term perspective.
A Quick Note on Data Science and it’s applicability to Fraud Monitoring & Detection –
Various posts in this blog have discussed the augmented capability of financial organizations to acquire, store and process large volumes of data using commodity (x86) hardware. At the same time, technologies such as Hadoop and Spark have enabled the collection, organization and analysis of Big Data at scale. The convergence of cost effective storage and scalable processing allows us to extract richer insights from data. These insights can then be operationalized to provide commercial and social value. Data science is a term that refers to the process of extracting meaningful insights from large volumes of structured and unstructured data. Data science is about scientific exploration of data to extract meaning or insight, and the construction of software systems to utilize such insights in a business context. This involves the art of discovering data insights combined with the science of operationalizing them. A data scientist uses a combination of machine learning, statistics, visualization, and computer science to extract valuable business insights hiding in data and builds operational systems to deliver that value. Data Science based approaches are core to the design and architecture of a Fraud Detection System. Data Mining techniques range from clustering and classification to find patterns and associations among a large group of data. The machine learning components are classified into two categories: ‘supervised’ and ‘unsupervised’ learning. These methods seek for accounts, customers, suppliers, etc. that behave ‘unusually’ in order to output suspicion scores, rules or visual anomalies, depending on the method. (Ref – Wikipedia).
It needs to be kept in mind that Data science is a cross-functional discipline. A data scientist is part statistician, part developer and part business strategist. The Data Science team collaborates with an extended umbrella team which includes visualization specialists, developers, business analysts, data engineers, applied scientists, architects, LOB owners and DevOps (ref – Hortonworks). The success of data science projects often relies on the communication, collaboration, and interaction that takes place with the extended team, both internally and possibly externally to their organizations.
Reference Architecture

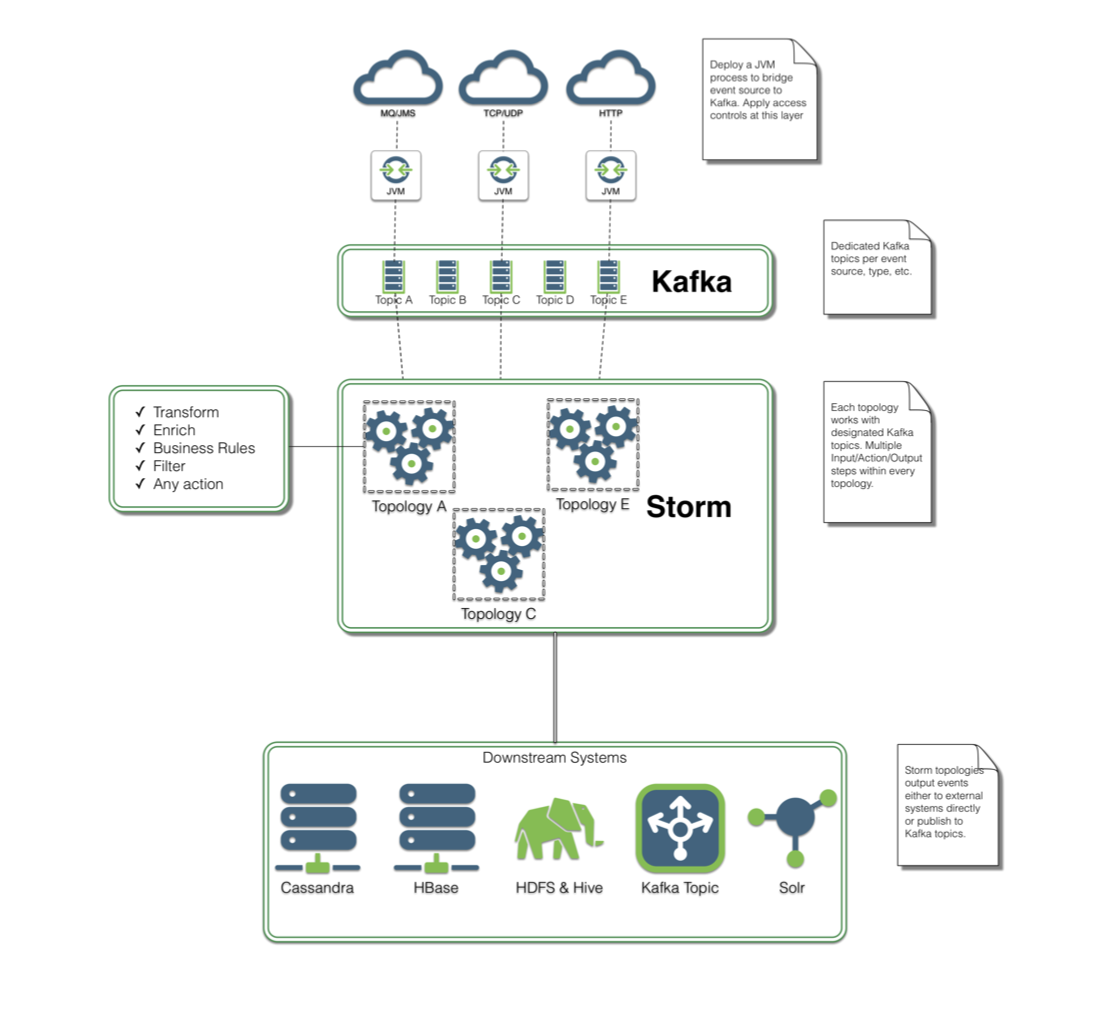
Illustration 1: Candidate Architecture Pattern for a Fraud Detection Application
The key technology components of the above reference architecture stack include:
- Information sources are depicted at the left. These encompass a variety of machine and human actors either transmitting potentially thousands of real time messages per second. These are your typical Credit Card Swipes, Online transactions, Fraud databases and other core Banking data.
- A highly scalable messaging system to help bring these feeds into the architecture as well as normalize them and send them in for further processing. Apache Kafka is chosen for this tier.Realtime data is published by Payment Processing systems over Kafka queues. Each of the transactions has 100s of attributes that can be analyzed in real time to detect patterns of usage. We leverage Kafka integration with Apache Storm to read one value at a time and perform some kind of storage like persist the data into a HBase cluster.In a modern data architecture built on Apache Hadoop, Kafka ( a fast, scalable and durable message broker) works in combination with Storm, HBase (and Spark) for real-time analysis and rendering of streaming data. Kafka has been used to message geospatial data from a fleet of long-haul trucks to financial data to sensor data from HVAC systems in office buildings.
- A Complex Event Processing tier that can process these feeds at scale to understand relationships among them; where the relationships among these events are defined by business owners in a non technical or by developers in a technical language. Apache Storm integrates with Kafka to process incoming data. Storm architecture is covered briefly in the below section.
- Once the machine learning models are defined, incoming data received from the Storm/Spark tier will be ingested into the models to predict outlier transactions or potential fraud. As a result of specific patterns being met that indicate potential fraud, business process workflows are created that follow a well defined process that is predefined and modeled by the business.
-
- Credit card transaction data comes as stream (typically through Kafka)
- An external system has information about the credit card holder’s recent location (collected from GPS on mobile device and/or from mobile towers)
- Each credit card transaction is looked up against user’s current location
- If the geographic distance between the credit card transaction location and user’s recent known location is significant (say 100 miles), the credit card transaction is flagged as potential fraud


Illustration 2 :External Lookup Pattern for a Fraud Detection Application (Sheetal Dolas – Hortonworks)
- Data that has business relevance and needs to be kept for offline or batch processing can be handled using the storage platform based on Hadoop Distributed Filesystem (HDFS). The idea to deploy Hadoop oriented workloads (MapReduce, or, Machine Learning) to understand fraud patterns as they occur over a period of time.Historical data can be fed into Machine Learning models created in Step 1 and commingled with streaming data as discussed in step 2.
- Horizontal scale-out is preferred as a deployment approach as this helps the architecture scale linearly as the loads placed on the system increase over time
- Output data elements can be written out to HDFS, and managed by HBase. From here, reports and visualizations can easily be constructed.
- One can optionally layer in search and/or workflow engines to present the right data to the right business user at the right time.
{kind=link}
Messaging Broker Tier
The messaging broker tier (based on Apache Kafka) is the first point of entry in a system. It fundamentally hosts a set of message queues. The broker tier needs to be highly scalable while supporting a variety of cross language clients and protocols from Java, C, C++, C#, Ruby, Perl, Python and PHP. Using various messaging patterns to support real-time messaging, this tier integrates application, endpoints and devices quickly and efficiently. The architecture of this tier needs to be flexible so as to allow it to be deployed in various configurations to connect to customized solutions at every endpoint, payment outlet, partner, or device.

Illustration 3: Multistage Data Refinery Pipeline for a Fraud Detection Application
Apache Storm is an Open Source distributed, reliable, fault – tolerant system for real time processing of large volume of data. Spout and Bolt are the two main components in Storm, which work together to process streams of data.
- Spout: Works on the source of data streams. In this use case, Spout will read realtime transaction data from Kafka topics.
- Bolt: Spout passes streams of data to Bolt which processes and passes it to either a data store or another Bolt.

Illustration 3: Kafka-Storm integration
Storage Tier
There are broad needs for two distinct data tiers that can be identified based on business requirements.
- Some data needs to be pulled in near realtime, accessed in a low latency pattern as well as have calculations performed on this data. The design principle here needs to be “Write Many and Read Many” with an ability to scale out tiers of servers
- In memory technology based on Spark is very suitable for this use case as it not only supports a very high write rate but also gives users the ability to store, access, modify and transfer extremely large amounts of distributed data. A key advantage here is that Hadoop based architectures can pool memory and can scaleout across a cluster of servers in a horizontal manner. Further, computation can be pushed into the tiers of servers running the datagrid as opposed to pulling data into the computation tier.
- As the data volumes increase in size, compute can scale linearly to accommodate them. The standard means of doing so is through techniques such as data distribution and replication. Replicas are nothing but copies of the same segment or piece of data that are stored across (aka distributed) a cluster of servers for purposes of fault tolerance and speedy access. Smart clients can retrieve data from a subset of servers by understanding the topology of the grid. This speeds up query performance for tools like business intelligence dashboards and web portals that serve the business community.
- The second data access pattern that needs to be supported is storage for data that is older. This is typically large scale historical data. The primary data access principle here is “Write Once, Read Many.” This layer contains the immutable, constantly growing master dataset stored on a distributed file system like HDFS. Besides being a storage mechanism, the data stored in this layer can be formatted in a manner suitable for consumption from any tool within the Apache Hadoop ecosystem like Hive or Pig or Mahout.
The final word [1] –
Since 2009, PayPal has been building and modifying its fraud analytics systems, incorporating new open-source technologies as they have evolved. For example, the company uses Hadoop to store data, and related analytics tools, such as the Kraken. A data warehouse from Teradata Corp. stores structured data. The fraud analysis systems run on both grid and cloud computing infrastructures.
Several kinds of algorithms analyze thousands of data points in real-time, such as IP address, buying history, recent activity at the merchant’s site or at PayPal’s site and information stored in cookies. Results are compared with external data from identity authentication providers. Each transaction is scored for likely fraud, with suspicious activity flagged for further automated and human scrutiny, Mr. Barrese said.
For example, “a very bad sign” is when one account shows IP addresses from 10 parts of the world, Dr. Wang said, because it suggests the account might have been hacked.
The system tags the account for review by human experts, she said. “They might discover that the IP addresses are at airports and this guy is a pilot,” she said. Once verified, that intelligence is fed back into PayPal’s systems. Humans don’t make the system faster, but they make real-time decisions as a check against, and supplement to, the algorithms, she said.
The combination of open-source technology, online caching, algorithms and “human detectives,” she said, “gives us the best analytical advantage.”
References –
[1] “PayPal fights Fraud With Machine Learning and Human Detectives” – From WSJ.com
http://blogs.wsj.com/cio/2015/08/25/paypal-fights-fraud-with-machine-learning-and-human-detectives/
2 comments
Hey, I am working on fraud detection using hadoop and since i am new to hadoop environment, i dont know where to start with. So could please provide me any beginner’s guide or sample codes if you have any.
Thanks
I have found this to be an excellent guide –
https://www.wiley.com/enus/Fraud+Analytics+Using+Descriptive%2C+Predictive%2C+and+Social+Network+Techniques%3A+A+Guide+to+Data+Science+for+Fraud+Detection-p-9781119133124